
Metodología de trabajo con i-Tree Canopy, el software para estimar la cobertura arbórea y los beneficios de los árboles en un área determinada con un proceso de muestreo aleatorio.
Qué es i-Tree Canopy
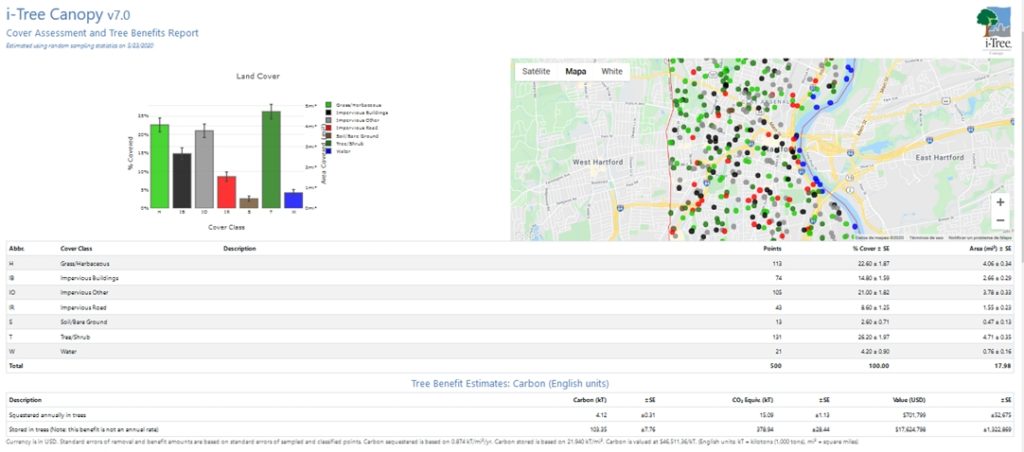
i-Tree Canopy es una solución cuyo objetivo es la estimación estadística de la cobertura arbórea y otros tipos de cubiertas a través de imágenes de satélite que ofrece el servicio de Google Maps. La cobertura arbórea es la superficie del suelo que está cubierto por la proyección vertical de las copas de los árboles. A partir de esta estimación y considerando determinadas variables que definen el beneficio ambiental que genera el arbolado, permite estimar estos beneficios y valorarlos económicamente.
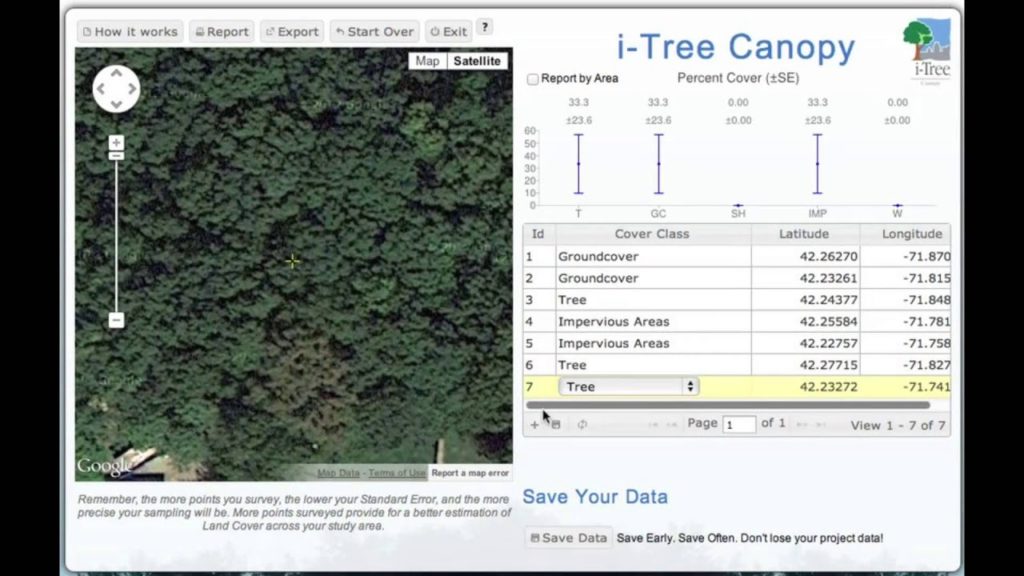
La aplicación web i-Tree Canopy consta de un visor con la información de Google Maps donde se muestra la imagen satélite de la zona de estudio. La estimación de la cobertura arbórea se realiza a partir de la clasificación de la superficie de una serie de puntos aleatorios que genera el programa.
Cómo trabaja i-Tree Canopy
A la hora de utilizar i-Tree Canopy hay varios pasos que son necesarios para lograr hacer una estimación de la biomasa lo más certera posible (Figura 1).
Definición del área de estudio
En primer lugar, hay que definir el área de estudio que se pretende analizar. Hay dos maneras posibles:
- dibujando sobre el visor de Google Maps el perímetro de la zona de estudio
- cargando una capa en formato shape que contenga los polígonos digitalizados. Para que los polígonos se puedan representar en el visor web, la capa tiene que estar en con coordenadas en geográficas
Una vez que se tiene dibujada el área que se pretende analizar, hay que definir las clases de cubiertas que se quieren estudiar. Con esta herramienta se pueden definir todas las clases que se quieran. El programa pone por defecto dos clases:
- Tree: para referirse a la cobertura arbórea
- Non-Tree: para referirse a las demás coberturas
Aunque se pueden definir tantas clases como se quieran es importe que haya al menos una clase que considere únicamente coberturas arbóreas.
Definición de las variables de los beneficios ambientales
A continuación, se define la captación varios componentes atmosféricos por parte del arbolado a partir de la propuesta de la Agencia de Protección Ambiental (EPA) de los estados Unidos (U.S. Environmental Protection Agency). El programa por defecto sugiere unos valores de captación cuya fuente es el modelo de estudio “Air pollution removal by urban trees and shrubs in the United States” (Nowak et al., 2006). Tanto los valores de los componentes atmosféricos como las unidades, que se muestran en el sistema anglosajón, se pueden cambiar por los valores que se consideren oportunos.
Categorización y generación de los puntos
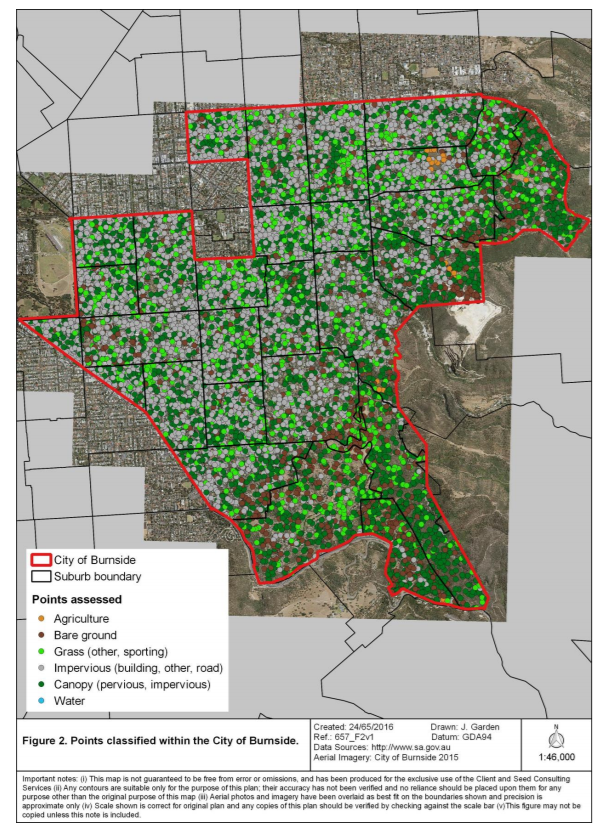
Una vez definidas las clases de las coberturas, el programa crea al azar puntos que se distribuyen de forma aleatoria por toda la zona de estudio. A medida que los puntos de control se van generando, es necesario asignar a cada cual la clase asociada a la superficie que se está fotointerpretando. Estas clases, que se han definido previamente, pueden ser tanto coberturas arbóreas como láminas de agua, suelo desnudo, carreteras y todas las categorías superficiales que se puedan discernir.
La fotointerpretación será de mayor precisión y más categorías se podrán discriminar cuanto mayor sea la resolución espacial de las imágenes, es decir, cuanto más pequeños sean los píxeles. A partir de este proceso el sistema genera un indicador estadístico del error de la estimación de la cobertura, el error estándar (SE). Este error disminuirá a medida que generemos más puntos de control para la zona de estudio y es necesario que haya un mínimo de puntos para que el error estándar sea lo suficientemente bajo y poder tener la certeza suficiente de que la estimación es correcta.
Para un área de estudio pequeña, como pueden ser varias manzanas de un barrio, habría que generar unos 300 puntos aleatorios. Para áreas más grandes, como por ejemplo el Parque del Retiro de Madrid (120 Ha), habría que generar en torno a 400-500 puntos. Para superficies muy grandes, como puede ser una ciudad como Madrid, se tienen que generar alrededor de 4.000-5.000 puntos. La cantidad de puntos también dependerá de otros factores, como es la heterogeneidad de coberturas de la zona de estudio, pero es imprescindible considerar el error estándar para que esté por debajo del 2%.
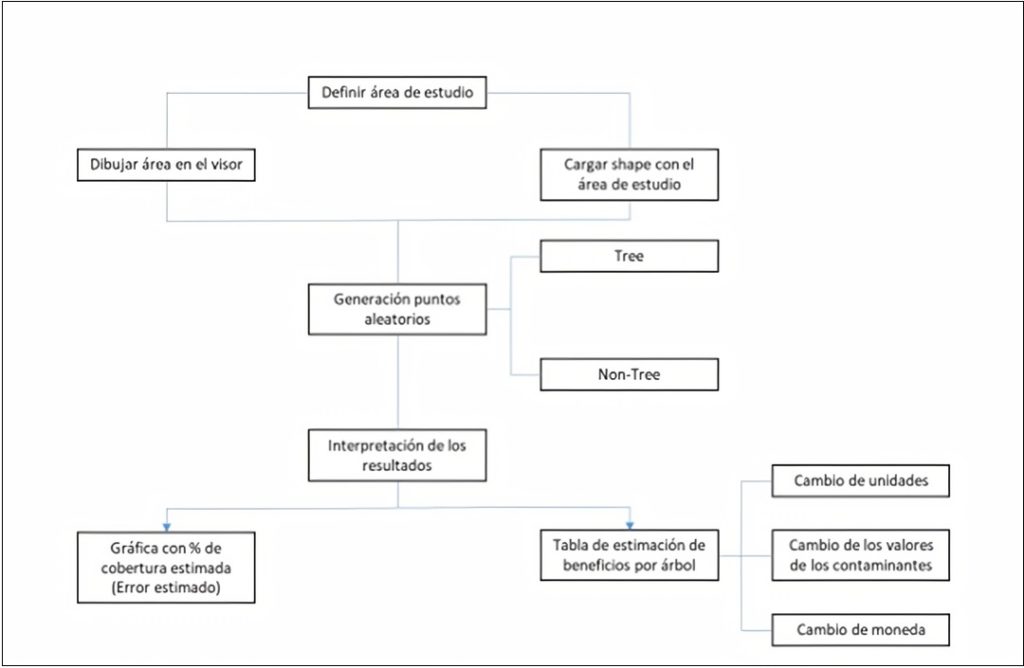
Generación de resultados
Por último, el sistema obtiene la superficie de cobertura arbórea extrapolando las proporciones de cada una de las clases de puntos a la superficie de la zona de estudio. Finalmente, a partir de la superficie de la cobertura arbórea se obtienen los beneficios ambientales considerando las variables definidas anteriormente.
Conclusiones
Ventajas
- El programa es gratuito, intuitivo y fácil de usar
- Se puede hacer una evaluación de la cobertura arbórea de forma rápida
- La precisión se puede aumentar fácilmente agregando y clasificando más puntos de control, lo que permite un aumento de la precisión muy rápida
- Se pueden llevar a cabo análisis de coberturas por sub-áreas, por ejemplo, el análisis de la cobertura arbórea de un barrio o de un conjunto de manzanas
Desventajas
- Las imágenes de Google pueden ser difíciles de interpretar en todas las áreas debido a una resolución de imagen relativamente baja. El tamaño del píxel de imagen, las condiciones ambientales o la mala calidad de imagen puede dificultar la labor de la fotointerpretación a la hora de distinguir entre árboles y arbustos
- La estimación estadística presenta muchas limitaciones frente a otros sistemas de clasificación supervisada o frente a los datos de inventarios de arbolado urbano disponibles en muchos casos
- Una de las limitaciones de este programa es que la exactitud del análisis depende de la destreza de la fotointerpretación a la hora de categorizar las clases
- No ofrece ningún método de validación de la fotointerpretación que se ha hecho a la hora de categorizar los puntos
- A la hora de hacer un cálculo de los elementos captados por las coberturas arbóreas, el programa no permite discriminar por especies y aunque se pudiera hacer esa discriminación, resultaría casi imposible distinguir entre estas con las imágenes de satélite que ofrece el servicio de Google
Bibliografía
- Forest Research – Urban Forestry Research Group (2019). Step-by-step guide to conducting an iTree Canopy study [PDF]. Web de consulta: https://www.forestresearch.gov.uk/research/i-treeeco/urbancanopycover/ [Acceso 20 de febrero de 2020]
- Herramienta i-Tree Canopy (Visor web)
- Hirabayashi, Sitoshi (2014). i-Tree Canopy Air Pollutant Removal and Monetary Value Model Descriptions. The Davey Institute, State University of New York
- i-Tree. Tools for Assessing and Managing Forests & Community Tres (2011). i‐Tree Canopy Technical Notes [PDF]. Web de consulta: https://www.itreetools.org/support/resourcesoverview/i-tree-methods-and-files [Acceso 19 de febrero de 2020]
- Nowak, David J.; Crane, Daniel E.; Stevens, Jack C. (2006). Air pollution removal by urban trees and shrubs in the United States. Urban Forestry & Urban Greening. 4 (3-4): 115-123 https://doi.org/10.1016/j.ufug.2006.01.007
- Nowak, David J. (2013). A Guide to Assessing Urban Forests. U.S. Department of Agriculture, Forest Service, Northern Research Station. 4 p
Este obra está bajo una Licencia Creative Commons Atribución 3.0 UnportedBootstrap is a front-end framework of Twitter, Inc. Code licensed under MIT License.Font Awesome font licensed under SIL OFL 1.1.






